In this blog, I will introduce YOLO (version 1) algorithm. YOLO now has been a popular algorithm on Object Detection because of its speed and simple structure.
Original paper: You Only Look Once: Unified, Real-Time Object Detection
Architecture
Pipeline:
- Divide the input image into S*S grid cells.
- Put each cell into a CNN and output B predicted bounding boxes and each box has a confidence score.
- Compute loss and training.
- Use pre-trained model to predict.
Grid Cell
Firstly, YOLO divides input image into $ S\times S $ grid cells (Picture 1). Picture 1
Picture 1
Next, each cell will produce $ B $ bounding boxes (also called predicted box or bbox). Each bounding box contains 5 predictions: center point coordinate $(x, y)$ of bbox, height $h$ and width $w$ of bbox and a conference score $S_{con}$. The original system sets $ S=7, B=2 $. For example, in Picture 2, bbox1(yellow) and bbox2(blue) are two predicting boxes of the cell(red). $(x_1, y_1, h_1, w_1)$ belong to bbox1.(x_2, y_2, h_2, w_2) belong to bbox2. Picture 2
Picture 2
In addition, each bbox will have a conference score $S_{con}$ of predicted bbox. The equation is shown below:
$$S_{con} = Pr(object)*IOU$$
$Pr(object)$: the probability of a bbox contains the object.
$IOU$: the intersection over union between the bbox and ground truth box. For example, in Picture 2, the conference score of bbox1 will be
$$S_{con1}=\frac{area_{shadow}}{area_{union}}\leq1$$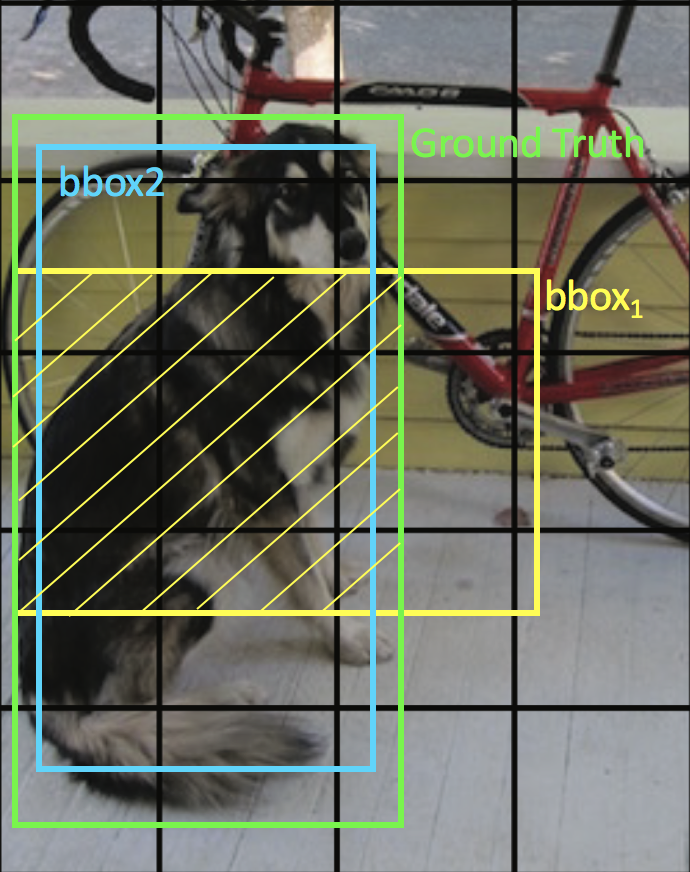 Picture 3
Picture 3
Then, each cell will produce class probability $Pr(class_i|object)$ (the detected object belongs to a particular class), every category has one probability.
In the paper, they use PASCAL VOC dataset so the number of class $C$ is 20.
Thus, the main job in YOLO is to predict a $(7,7,2\times5+20)$ tensor through a CNN network.
CNN Structure
The deep convolutional neural network used in YOLO is inspired by GoogLeNet, and has 24 convolutional layers followed by 2 fully connected layers. The details are shown in Picture 4.
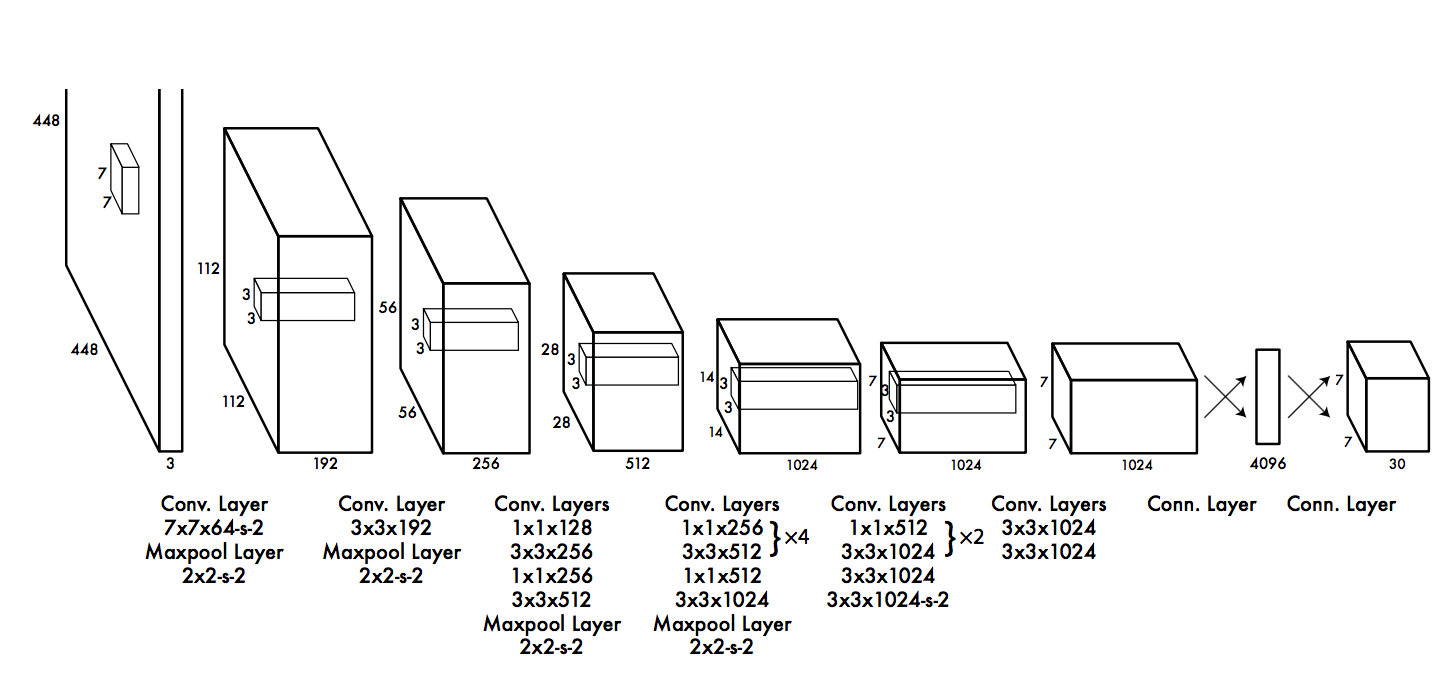
Picture 4. CNN Architecture
Training
Loss Computation

Picture 5. Loss Computation
loss = localization loss(1-2 lines) + confidence loss(3-4 lines) + classification loss(5 line)
For confidence loss, the target values of IoU and Pr(object) are:
IoU=1.
Pr(object)=1, if the cell contains the center point of ground truth;
Pr(object)=0, else.
Prediction
In prediction part, firstly, we need to compute
class-specific confidence score. The equation is shown below:
${class\ confidence\ score}=P_r(class_i)\times IoU$
$\qquad\qquad\qquad\qquad\qquad\ = box\ confidence\ score \times class\ probability$
In other words, let each box confidence score time each class probability. Thus, we will get $20\times(7\times7\times2)=20\times98$ class-specific confidence score.
Next, for each class, set zero if the $score<threshold$, and run NMS algorithm to delete redundant bboxes. (see reference[2] for the details of prediction and NMS)
References
[1] https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088
[2]https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.g137784ab86_4_2069
[3]https://blog.csdn.net/u014380165/article/details/72616238
[4]https://arxiv.org/abs/1506.02640